vasa
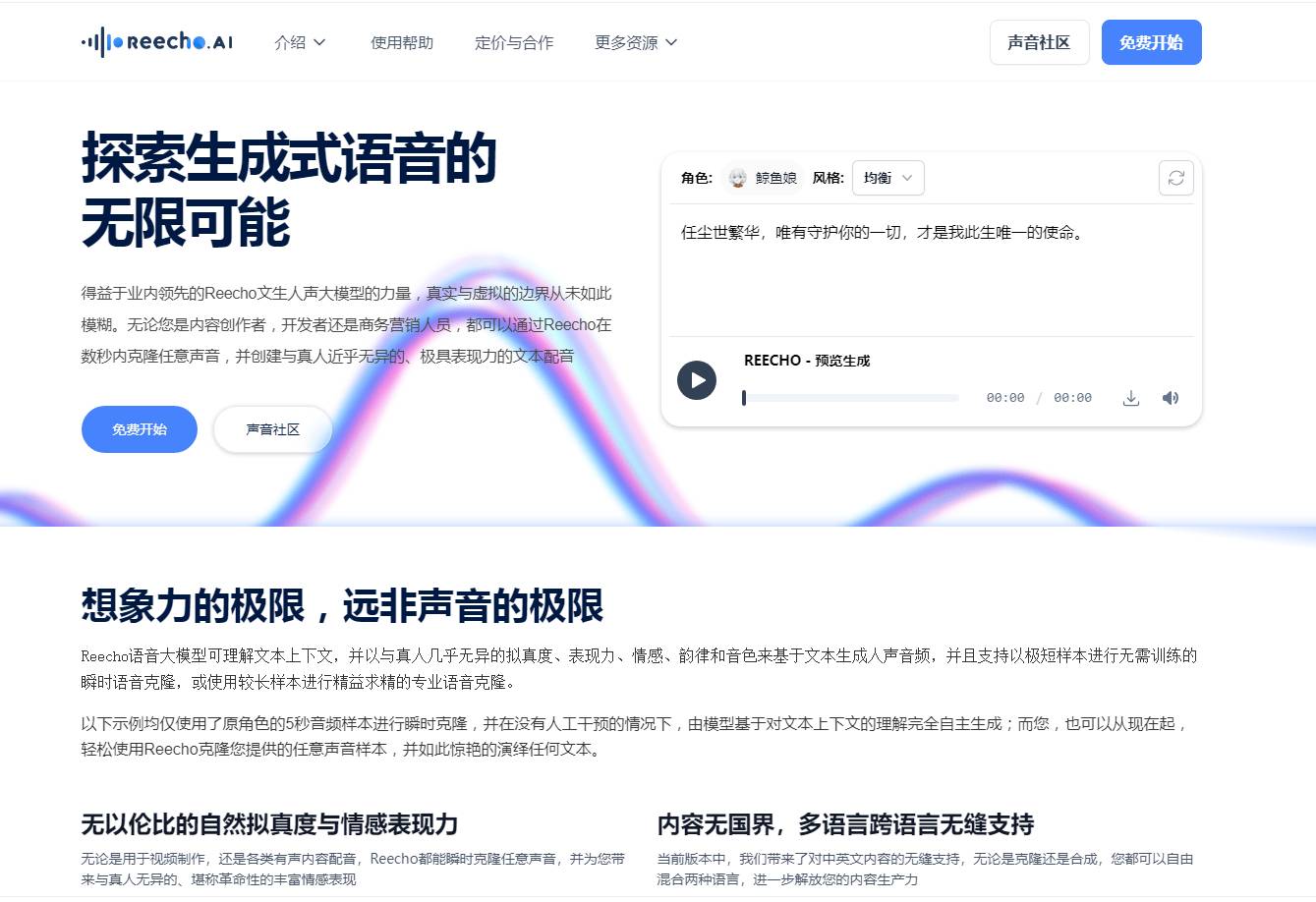
微软VASA-1是微软亚洲研究院开发的前沿AI技术,能将单张肖像照片与语音音频结合,实时生成逼真会说...
vasa是什么?
微软VASA-1是微软亚洲研究院开发的前沿AI技术,能将单张肖像照片与语音音频结合,实时生成逼真会说话的面部视频。它实现精准唇音同步,还原丰富细腻的面部表情,呈现自然的头部动作,让人物形象生动“复活”。支持真实或AI生成人像,广泛适用于虚拟交互、数字人等领域。
VASA-1技术功能与应用介绍
VASA-1是微软亚洲研究院推出的一项突破性人工智能技术,能够将单张静态肖像照片与语音音频结合,实时生成具有高度真实感的说话人脸视频。通过先进的深度学习模型,vasa实现了精准的唇音同步、丰富的面部微表情还原以及自然的头部运动模拟,使人脸动画看起来栩栩如生。无论是AI生成的图像还是真实人物照片,例如公众人物或普通用户的照片,都能在音频驱动下“开口说话”,赋予静态图像强烈的动态表现力。
该技术不仅在视觉效果上达到超现实水准,还具备低延迟生成能力,适用于虚拟人、在线教育、数字助手等多个场景。vasa的核心优势在于其对复杂面部动作的精细建模,包括眼神变化、眉毛动作和情绪表达,极大提升了交互的真实感和沉浸感。
如何使用VASA-1及相关访问方式
目前VASA-1作为研究项目,尚未向公众提供开放的在线使用平台,但开发者和研究人员可通过官方渠道了解技术细节与潜在合作机会。想要体验或探索vasa的技术能力,可访问其官方网站 https://www.microsoft.com/en-us/research/project/vasa-1/ 获取最新信息。网站中提供了详细的论文、演示视频和技术文档,帮助用户理解系统的工作原理与输入输出要求。
使用该技术需准备一张清晰的人脸正面图像和一段目标语音音频,系统将自动合成对应的动态说话视频。虽然当前不支持直接上传生成,但未来有望集成至微软相关AI服务中,为创意产业和企业应用带来革新动力。
相关推荐 Related